Artificial neural networks rely heavily on large sets of data to train their models. However, with the constantly evolving data privacy regulations around the world, obtaining high-quality data becomes increasingly challenging, mainly due to security or privacy reasons. Read more and find out how to generate synthetic time series for you machine learning models.
The rise of new technologies like generative AI demands that businesses innovate to stay ahead of the competition. Without access to secure training data, engineers cannot experiment and push new technologies forward. The lack of diverse and secure datasets on a significant scale makes it challenging to train predictive models. Synthesizing time series data can be challenging because it requires preserving the relationships between variables and time, as well as the relationships between variables themselves. A successful time-series model should not only capture the features and distributions within each time-point, but also the complex dynamics of these features across time.
Generating the synthetic data
The most important part of time series synthesis is the generator. Of course, I won’t develop it from scratch but I will use a package – Gretel-synthetics generator. The package contains a set of synthetic data generators for structured and unstructured text and time series featuring differentially private learning.
Prepare the real data
To run the generator we need to prepare real data which will be used to create the synthetic time series. The synthetic data’s statistical properties should be as similar as possible to the real data. I got the real open source data a bike sharing demand, which as the name suggests, contains number of bike shared among users.
def get_data():
bike_sharing = fetch_openml("Bike_Sharing_Demand", version=2, as_frame=True)
df = bike_sharing.frame
return df['count']
0 16
1 40
2 32
3 13
4 1
...
17374 119
17375 89
17376 90
17377 61
17378 49
When my data is ready, I need to reshape it to match the requirements of the generator model class.
MAX_SEQUENCE_LEN = 100
PLOT_VIEW = 600
# Get real data
bike_count = get_data()
# Prepare data format
features_2d = to_windows(bike_count, MAX_SEQUENCE_LEN)
features_3d = np.expand_dims(features_2d, axis=2)
The to_windows function implements a sliding windows and converts a time series into a sequence of vectors. I presented details of the function here.
Create the GAN
In the next step, I prepare the generating model. The model definition is the main function in our code. We have to specify, among others max_sequence_len – the length of our time series, sample_len batch_size…
The documentation for DGAN and DGANConfig be found here.
def create_model(features):
model = DGAN(DGANConfig(
max_sequence_len=features.shape[1],
sample_len=20,
batch_size=min(1000, features.shape[0]),
apply_feature_scaling=True,
apply_example_scaling=False,
use_attribute_discriminator=False,
generator_learning_rate=1e-4,
discriminator_learning_rate=1e-4,
epochs=100,
))
model.train_numpy(
features,
feature_types=[OutputType.CONTINUOUS] * features.shape[2],
)
return model
Finally, I’m the model is ready to run. As the training takes a long time, I save the model to make it easier to tamper with the code or debug it. For this purpose, I use SERIALISED flag.
# Create the model
if not SERIALISED:
model = create_model(features_3d)
model.save(model_dump)
else:
model = DGAN.load(model_dump)
# Generate synthetic data
BATCHES_NUMBER = 60
_, synth_chunk = model.generate_numpy(BATCHES_NUMBER)
synthetic = np.concatenate(
synth_chunk[0:synth_chunk.shape[0], :, :], axis=0)
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(6, 12),
layout='constrained')
Results
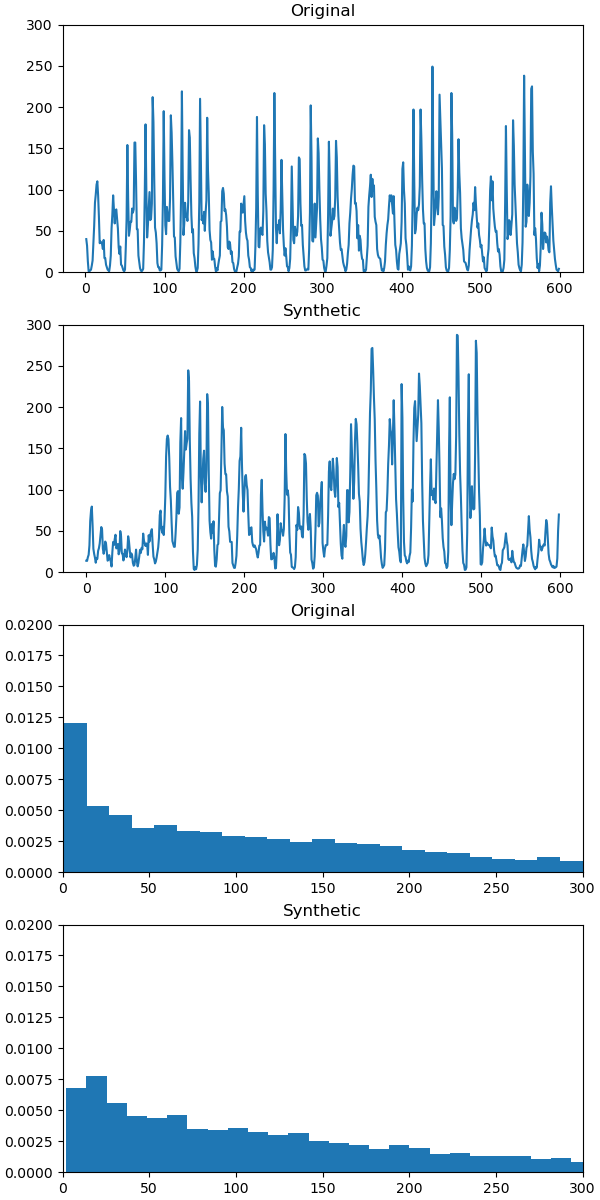
The results are promising. The time series are similar. By similarity, I mean that the series should keep similar statistical properties like mean, variance or autocorrelation. These two first properties look similar. However, for the autocorrelation, it is hard to assess without a plot. As you can see in the figure, the autocorrelation is roughly similar, but not perfect.
Code
Summary
Generating synthetic time series can be challenging. There are few open-source tools available for this purpose like ydata-synthetic. In this post, I employed Gretel-synthetics generator. The superficial test shows that this tool is capable of generating synthetic time series of decent quality. However, to fully examine this tool, more tests with different types of time series are needed.